Here is how to find duplicate files in Linux Ubuntu. Also, learn how to delete duplicate files in Linux via command line. fdupes is a command line tool to find and delete duplicate files in Linux Ubuntu.
fdupes Command
The fdupes easily finds duplicate files in a given set of directories. It searches the given path for duplicate files. Such files are found by comparing file sizes and MD5 signatures, followed by a byte-by-byte comparison.
Install fdupes
fdupes finds duplicate files in a given set of directories. It searches the given path for duplicate files. Such files are found by comparing file sizes and MD5 signatures, followed by a byte-by-byte comparison.
Run the following commands to install fdupes on Ubuntu Systems:
$ cd fdupes
$ autoreconf –install
$ ./configure
$ make
$ sudo make install
How to use fdupes?
Using fdupes is easy and simple. Simplye execute the fdupes command followed by the path to a directory that you wish to search in for duplicate files.
For finding duplicates, you have execute the command $ fdupes /path/to/some/directory This command will only look in directory specified and will print out all the duplicate files.
It will not look into sub-directories. To look also in sub-directories, add the “-r” command option. It denotes “recursively” and will force the command to look for duplicate files in all the sub-directories.
Examples of using fdupes
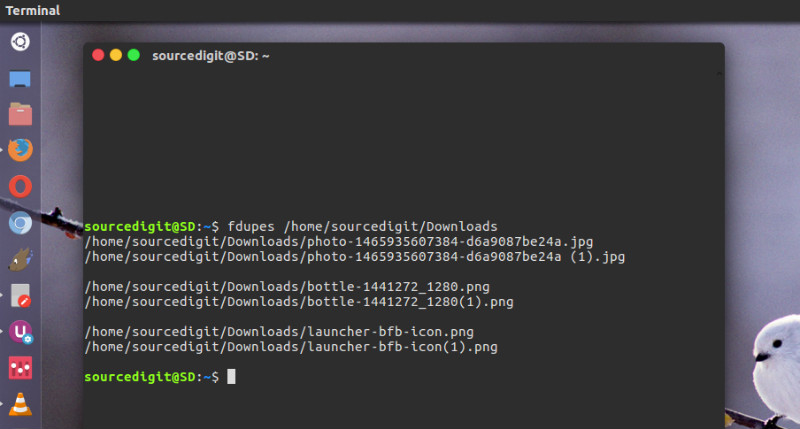
So to find duplicate files in Downloads directory, run the command fdupes /home/sourcedigit/Downloads [replace sourcedigit with yours).
It will list all duplicate files in the directory Downloads. Note that the above command will not look for duplicate files in subdirectories.
To find all the duplicate files in subdirectories, run the command with option -r. It will recursively search all subdirectories inside /Downloads directory for duplicate files and accordingly list them on the screen.
Deleting Duplicate Files
Please note that the fdupes command do not automatically delete any files. To delete the duplicate files use -d –delete. It will prompt user for files to preserve, deleting all others.
If you want to delete all the duplicate files, run the command $ fdupes -d /path/to/directory.
Command Options
There are many command options that can be used with fdupes.
For example, to see the the size of files use the option -S. Use -m –summarize to get a summary of the duplicate files information.
Popular command options to use:
- -r –recurse
for every directory given follow subdirectories encountered within - -R –recurse:
for each directory given after this option follow subdirectories encountered within (note the ‘:’ at the end of option) - -s –symlinks
follow symlinked directories - -H –hardlinks
normally, when two or more files point to the same disk area they are treated as non-duplicates; this option will change this behavior - -n –noempty
exclude zero-length files from consideration - -f –omitfirst
omit the first file in each set of matches - -A –nohidden
exclude hidden files from consideration - -1 –sameline
list each set of matches on a single line - -S –size
show size of duplicate files - -m –summarize
summarize duplicate files information - -q –quiet
hide progress indicator - -d –delete
prompt user for files to preserve, deleting all others. - -N –noprompt
when used together with –delete, preserve the first file in each set of duplicates and delete the others without promptingthe user - -v –version
display fdupes version - -h –help
displays help
NOTE:
- When using -d or –delete, care should be taken to insure against accidental data loss.
- When used together with options -s or –symlink, a user could accidentally preserve a symlink while deleting the file it points to.
- Furthermore, when specifying a particular directory more than once, all files within that directory will be listed as their own duplicates, leading to data loss should a user preserve a file without its “duplicate” (the file itself!).